2024 우수잡지


-MPLAB Software Updates-KR 466x58H.jpg)


DFT를 향한 성능 저하 없는 상향식 접근방식

글/Geir Eide, Siemens Digital Industries Software
서론
대규모 SoC(System on Chip) 설계의 복잡성이 증가함에 따라 DFT(Design-For-Test)를 비롯한 모든 IC 설계 분야에 서 어려움을 겪고 있다. 이러한 어려움을 완화하기 위해 계층적 DFT는 패턴 생성 및 검증을 비롯하여 모든 DFT 구현이 칩 레벨이 아닌 코어 레벨에서 이루어지는 분할 정복 방식으로 사용된다. 그러나 계층적 DFT만으로는 더 이상 충분하지 않다.
많은 DFT 관리자들은 힘겹게 그리고 때로는 큰 비용을 치르면서 테스트 구현 노력과 제조 테스트 비용을 절충해야 하며 턴어라운드, 비용 및 품질 목표를 달성하기 위해 노력해야 한다.
이 백서에서는 코어 레벨 및 칩 레벨 DFT 요구사항을 분리하도록 설계된 기술인 Tessent SSN(Streaming Scan Network)의 기본 구성요소에 관해 설명한다. SSN 덕분에 DFT 엔지니어는 처음으로 구현 노력과 제조 테스트 비용을 절충할 필요 없이 실질적이고 효과적인 상향식 플로우를 통해 DFT를 구현할 수 있다.
테스트 과제
DFT 엔지니어가 현재 직면하고 있는 몇 가지 과제에 대해 자세히 살펴보겠다.
(1) 계획 및 레이아웃
기존의 계층적 핀-먹스(pin-mux) 스캔 테스트 접근방식과 병행하여 코어 그룹을 테스트하기 위해 스캔 채널 입력 및 출력은 여러 단계의 먹스를 통해 칩 레벨 핀에 직접 연결된다. 함께 테스트할 수 있는 코어는 먹스 네트워크를 기반으로 하므로 설계 흐름 초기에 결정되어야 한다. 더 복잡한 먹스 네트워크를 통해 유연성을 높일 수 있으나 이는 라우팅 혼잡으로 이어질 수 있다. 코어는 더 많고 테스트에 사용할 수 있는 칩 레벨 핀 수는 일정하므로 추가적인 코어 및 액세스 구성 그룹을 생성해야 한다. 이것은 DFT 구현 노력, 실리콘 면적, 패턴 리타겟팅 복잡성, 테스트 시간에 영향을 미친다.
코어를 테스트하는 데 필요한 테스트 사이클 수는 압축구성, 스캔 체인 길이, 코어당 테스트 패턴 수에 따라 결정된다. 테스트 계획에서 중요한 한 가지는 각 유선 연결 스캔 액세스 구성의 모든 구성에서 함께 테스트할 코어 그룹을 결정하는 것이다.
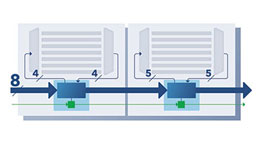
코어당 스캔 채널 수와 압축 구성이 고정된 선형적 상향식 플로우에서는 그림 1에 나온 것처럼 최적이 아닌 결과를 얻고 테스트 대역폭이 낭비될 수 있다. 함께 테스트되는 코어 간에 테스트 리소스의 균형이 유지되는 반복적 최적화를 통해 더 적절한 결과를 얻을 수 있다.
이 접근방식은 리소스 집약적이며 계층 레벨이 다양한 복잡한 설계에서는 실용적이지 못할 수 있다. 여러 설계에 사용되는 코어의 경우, 한 설계에 최적인 압축 구성이 다른 설계에서는 그렇지 못할 수 있다.
-1")
[그림 1] 계층적 DFT 절충: 구현 노력과 대역폭 관리
(2) 동일 코어의 효과적인 처리
동일한 코어 인스턴스에 대해 테스트 패턴 볼륨을 최적화하는 한 가지 방법은 동일한 최상위 핀에서 동일한 패턴을 스캔 입력에 보내는 것이다. 출력은 테스트 범위를 보장하고 진단 가능성을 보장하기 위해 종종 독립적으로 관찰된다. 코어 인스턴스당 적어도 하나의 출력 채널이 필요하므로 동시에 테스트할 수 있는 동일 코어 수를 제한할 수 있다. 또 다른 과제는 캡처 클록이 일반적으로 모든 코어에 동시에 적용된다는 것이다. 따라서 스캔 입력 핀 그리고 이를 통해 구동되는 모든 동일 코어 인스턴스 간에 파이프라인 단계 수가 같아야 한다. 코어 외부에 라우팅이나 로직이 없는 타일 구조에서는 이것이 어려울 수 있다.
(3) 교차되는 타일 기반 설계
타일 기반 레이아웃은 DFT 아키텍처의 복잡성과 제약을 가중시킨다. 코어는 한 코어에서 다음 코어로 연결이 이어질 수 있도록 서로 교차하는 형태로 설계되었기 때문에 사실상 최상위 라우팅이 없다. 코어 간 연결은 코어 사이에 있는 코어를 통해 이루어져야 한다. 탑 레벨에 있는 로직은 코어 내부로 이동되고 코어의 일부분으로 설계되어야 한다.
SSN의 장점
SSN은 테스트 데이터의 전달과 코어 레벨 DFT 요구사항을 분리한다. 즉, 코어 레벨 압축 구성이 칩 IO 제한과 완전히 별개로 정의될 수 있다. 어떤 코어를 동시에 테스트할 것인지가 핀 먹스 접근방식에서처럼 유선으로 선택되는 것이 아니라 프로그램 방식으로 선택된다.
이 개념은 DFT 계획 및 구현 노력을 획기적으로 줄여준다. 그림 2에 나와 있듯이, SSN에서는 값비싼 설계 반복 없이도 SoC에 가장 적합한 테스트 데이터 시간과 볼륨을 얻을 수 있기 때문에 DFT 구현 노력과 제조 테스트 비용을 절충해야 할 필요가 없다.
-2")
[그림 2] SSN은 구현 노력과 테스트 비용의 절충을 없앤다.
SSN을 사용하는 경우, 코어에 대한 압축 및 스캔 채널 수는 단순히 해당 코어에 대해 자체적으로 가장 작은 패턴 세트를 구성하는 방법에 의해서만 결정되어야 한다.
여러 설계에 사용되는 코어에 대해 압축을 한 번에 모두 구성할 수 있다. 각 설계에 대한 최적의 압축을 보장하기 위해 DFT를 변경할 필요가 없다. SSN은 각 코어에 무엇이 필요한지에 따라 사용 가능한 대역폭을 자동으로 분배하여 테스트 데이터에서 공백을 없앤다(그림 3).
-3")
[그림 3] SSN은 여러 테스트 비용 절감 기능을 통해 진정한 상향식 플로우를 지원한다.
SSN은 디커플링으로 인한 테스트 데이터 절약 외에도 테스트 비용을 절감하는 추가 기능을 제공한다. 이에 대해서는 이후 섹션에서 자세히 설명하겠다. 계획, 구현 및 테스트 비용 이점 외에도 SSN 아키텍처는 라우팅 및 타이밍 마감을 용이하게 하며, 교차하는 타일기반 설계와 완벽하게 호환된다.
이 모든 것이 모든 ATPG 패턴 유형 및 고장 모델을 지원하면서 가능하다. 또한 SSN은 모든 Tessent DFT 방법론 및 제품과 호환되며, 진단 및 수율 분석을 위한 모든 지원을 갖추고 있다.
(1) SSN 기술 및 개념
SSN은 버스 기반의 스캔 데이터 분배 아키텍처이다. 그림 4는 SSN을 사용하는 6-코어 설계의 간단한 예를 보여 준다. 각 코어에는 일반적으로 한 개의 SSH(Streaming Scan Host) 노드(하늘색 블록)가 포함되어 있다.
-4")
[그림 4] 6-코어 설계에 사용된 SSN
SSH는 SSN 버스에 전송된 데이터로 스캔 체인/채널을 로드 및 언로드하기 위해 로컬 스캔 자원을 구동한다. 그림에는 컴프레서/컴팩터가 하나만 나와 있지만, SSH 노드는 하나 이상의 EDT 컨트롤러, 압축되지 않은 스캔 체인 또는 이 둘의 조합과 연결될 수 있다.
각 SSH에는 두 개의 외부 인터페이스가 있다. 하나는 IEEE 1687 IJTAG 인터페이스이고, 다른 하나는 페이로드 스캔 데이터를 전송하고 한 SSH 노드를 다음 SSH 노드에 연결하는 병렬 데이터 버스이다. IJTAG 네트워크는 테스트 패턴 세트를 적용하기 전에 SSN 네트워크의 모든 노드를 구성하는 데 사용된다. 각 노드에는 활성 버스 폭, 구동 노드 시리즈에서의 위치, 스캔 패턴당 시프트 사이클 수, scan_enable 전환 타이밍 정보 등의 프로토콜 관련 정보가 로드된다.
이 설정 이후에 전체 스캔 테스트 패턴 세트가 병렬 SSN 버스에서 스트리밍되는 패킷 데이터로 적용된다. SSH는 패턴 세트당 한 번만 프로그래밍되며 설정 이후에 스캔 페이로드만 스트리밍된다. 각 패킷과 함께 opcode 또는 주소 정보를 보낼 필요가 없다. 각 SSH는 로드/언로드 및 캡처 단계 간 전환은 물론 개별 시프트 작업을 수행하는 등 코어에 대한 로컬 스캔 작업을 제어한다.
모든 스캔 신호 및 EDT 컨트롤 신호는 코어 로컬 SSN에 의해 생성된다. SSN 버스 폭은 칩 레벨 핀 가용성에 따라 선택되며 스캔된 코어의 수 및 로직 크기 그리고 각 코어의 EDT 컨트롤러에 필요한 채널 수와 무관하다. 따라서 각 코어에서 동일한 플러그 앤 플레이 인터페이스와 버스 폭을 스캔 테스트에 사용할 수 있기 때문에 SSN은 설계 평면도, 코어 수 또는 코어 콘텐츠가 바뀜에 따라 효율적으로 확장될 수 있다.
스캔 테스트 데이터를 SSN 버스를 통해 ‘패킷’으로 제공함으로써 버스 폭과 코어 채널 간의 상호 종속성이 가능하다. 패킷은 모든 활성 SSH 노드가 단일 내부 스캔 시프트 작업을 수행하는 데 필요한 모든 스캔 데이터를 의미한다. 테스터에서 제공하는 SSN 페이로드를 SSN 버스 경계를 가로지르는 연속적인 패킷 스트림으로 볼 수 있다.
두 블록을 동시에 테스트하고 있는 그림 5의 예를 생각해보자. 블록 A는 블록의 시프트 사이클당 5비트를 로드/언로드한다(5개의 EDT 채널이 있음). 블록 B에는 네개의 채널이 있다. 두 블록 모두가 한 번의 시프트 사이클을 수행하려면 9비트를 로드/언로드해야 한다.
-5")
[그림 5] 동시에 두 블록 테스트
기존의 핀-먹스 스캔 액세스 방법이었다면 9개의 칩 레벨 스캔 입력 핀과 9개의 스캔 출력 핀이 필요했을 것이다. SSN에서는 패킷 크기가 SSN 버스 폭(이 예에서는 8비트)과 별개로 9비트로 설정된다.
한 코어에서 다음 코어로 데이터를 전송하는 버스를 라우팅하면서 활성/비활성/우회 코어를 동적으로 제어할 수 있다는 것은 하드웨어를 변경하지 않고도 모든 코드 조합에 유연하게 액세스할 수 있다는 것을 의미한다.
핀 먹스 아키텍처와 달리 이러한 유연성은 라우팅 혼잡을 수반하지 않는다. 동시에 테스트할 코어들을 어떻게 그룹화할 것인지는 설계 시점에서 예측할 필요가 없다. 코어 그룹에서 ATPG를 수행하든 아니면 서로 다른 코어에서 패턴을 리타겟팅하든, 동일한 SSN 네트워크가 한 번에 한 코어에만 액세스하거나, 동시에 모든 코어에 액세스하거나, 그 중간의 형태를 띨 수 있다.
(2) 클록 스큐 및 버스 폭 관리
패킷이 여러 버스 폭에 걸치도록 동시에 여러 코어를 구동하고, 내부 시프트 주파수보다 외부 주파수가 빠르게 되면 그 결과 내부 코어 시프트 주파수의 제한을 넘어서지 않는 범위에서 데이터를 보다 신속하게 제공할 수 있다.
SSN 구현에서는 코어-내부 시프트 주파수를 100MHz로 제한하되 400MHz에서 더 빠른/좁은 버스를 실행하는 것이 일반적이다. 이것은 SoC 전반에서 SSN 클록의 균형을 맞추지 않고도 가능하다. SSN 클록은 각 코어 또는 코어 그룹 내에서 균형을 맞출 수 있지만, 시프트 주파수를 낮추는 것을 허용해서는 안 되는 클록 스큐가 이들 영역 사이에 있을 수 있다.
이 문제는 BFD(Bus Frequency Divider)/BFM(Bus Frequency Multiplier) 쌍을 사용하여 해결한다. 이 쌍은 디스큐 FIFO 역할을 한다. CTS(Clock Tree Synthesis) 영역을 통과할 때 빠르고 좁은 버스를 느리고 넓은 버스로 임시 변환함으로써 시프트 속도나 처리량에 영향을 주지 않고 더 많은 양의 클록 스큐를 수용할 수 있다. 회로적으로, FIFO는 SSN 데이터 경로의 파이프라인 단계처럼 작동한다. 동일한 개념을 활용하여 테스터에서 내부 스캔 체인까지의 처리량을 극대화할 수 있다.
(3) 시간 멀티플렉싱
대부분의 경우, 400MHz SSN 버스를 구현할 수는 있지만 200MHz 이상으로는 칩 레벨 핀을 통해 데이터를 시프트할 수 없다. SoC에 64개의 스캔 입력과 64개의 스캔 출력을 구현하기에 충분한 핀이 있다고 가정하자.
한 가지 옵션은 칩 전체에 64비트 버스를 구현하고 200MHz로 작동하는 것이다. 또는 그림 6과 같이, 데이터는 200MHz에서 64개 핀을 통해 칩에 스캔될 수 있으며 이 입력 스트림을 32비트 400MHz 버스로 변환하기 위해 스캔 입력과 첫 번째 SSH 사이에 BFM을 추가할 수 있다. 그리고 이 32비트 버스는 칩 전체에서 사용되며 SSH 노드를 32비트 버스와 연결한다. 출력 측에서는 SSN 출력 버스를 출력 핀을 구동하는 200MHz 64비트 버스로 다시 변환하기 위해 BFD 노드가 추가된다.
-6")
[그림 6] 시간 멀티플렉싱
(4) 테스트 시간 및 데이터 볼륨 최적화
코어-외부 테스트 모드에서 코어 간 인터페이스에 대한 ATPG가 실행되는 경우와 같은 상황에서는 영향을 받는 모든 코어의 캡처 사이클을 정렬해야 한다. SSN을 사용하면 각 코어가 독립적으로 시프트할 수 있도록 SSH가 프로그래밍되지만 모든 코어가 스캔 로드/언로드를 완료한 후에는 캡처가 동시에 수행된다.
또 다른 상황인, OCC가 포함된 래핑된 코어의 ATPG가 분리되어 실행되는 경우와 같은 상황에서는 다른 코어가 시프트하거나 캡처하는 지와 관계없이 각 코어가 캡처할 수 있을 때 캡처를 수행하는 것이 더 효과적이다. 짧은 스캔 체인이 있는 코어는 다른 코어가 시프트를 완료할 때까지 기다릴 필요 없이 캡처할 수 있다. 서로 다른 코어의 패턴 수가 크게 차이가 나는 경우가 종종 있다.
기존의 리타겟팅 방식은 더 적은 수의 패턴으로 코어를 보완하기 때문에 데이터 및 테스트 시간이 낭비된다. SSN은 각 코어에 사용되는 대역폭을 프로그래밍 방식으로 변경함으로써 코어 간의 시프트 길이/패턴 개수 불균형을 줄인다. 다른 코어보다 패턴 세트 전반에서 훨씬 적은 수의 전체 시프트 사이클이 필요한 코어는 더 적은 수의 패킷당 비트로 전송될 수 있다. 예를 들어 채널 이 4개인 코어는 패킷당 4비트를 할당할 필요가 없다. 속도를 낮춰 패킷당 1비트만 전송하여 모든 패킷이 아니라 4개 패킷마다 내부적으로 시프트할 수 있다.
그 결과, 총 패킷 수는 그대로 유지되지만, 패킷 크기가 감소하여 전체 테스트 시간이 단축된다. 다음 섹션에서는 동일 코어 인스턴스가 여러 개 있을 때 가능한 추가적인 테스트 최적화에 관해 설명한다.
(5) 동일 코어의 효율적인 테스트
CPU, GPU, AI 가속기를 비롯한 많은 SoC는 병렬 처리로 처리량을 높이며 여러 번 복제되는 다수의 코어를 포함한다. 핀 먹스 아키텍처에서는 스캔 입력은 동일 코어 인스턴스로 브로드캐스트할 수 있지만, 일반적으로 스캔 출력은 무손실 매핑 그리고 고장 진단을 위한 관측 가능성을 보장하기 위해 독립적으로 관찰된다. SSN은 사용 가능한 칩 레벨 핀 수와 관계없이 거의 일정한 테스트 시간에 동일 코어 인스턴스를 얼마든지 테스트할 수 있는 확장 가능한 방법을 제공한다. 그림 7에서와 같이 테스트 입력, 예상 출력 값 및 compare/nocompare 마스크 데이터가 각 패킷 내에서 스캔된다. 그런 다음 각 코어는 자체 온칩 비교를 수행한다. 집계된 각 시프트별 상태 비트 및 코어당 인스턴스 통과/실패 스티키 비트는 테스터의 관찰자이다.
-7")
[그림 7] 개수와 관계없이 동일 코어 인스턴스 테스트
각 시프트별 상태 비트는 언로드를 위해 패킷에 타임슬롯이 할당된다. 패킷은 모든 동일 코어 인스턴스(또는 그 일부)에서 특정 채널/시프트 사이클의 통과/실패 상태를 집계한다. 이 비트가 실패를 나타내는 경우, 어떤 코어 레벨 비트에 오류가 있는지를 알 수 있지만, 해당 오류의 원인인 코어 인스턴스는 정확히 알 수 없다. SSH당 통과/실패 스티키 비트는 패턴 세트의 사이클/채널에서 이 SSH에 의해 관찰된 스캔에 오류가 있는지를 나타낸다. 이 SSH당 비트는 패턴 세트의 끝에 있는 IJTAG를 통해 언로드되어 실패한 코어를 신속하게 식별하고(예비 코어가 있는 설계의 경우) 고장 진단에 도움을 준다.
SSH당 1개 장애 비트보다 더 세부적인 정보가 필요한 경우, SSH에 연결된 채널 출력당 스티키 비트를 생성할 수 있다.
(6) 타일 기반 설계
SSN은 코어 외부에 라우팅이 없는 타일 기반 설계에서 코어 교차를 지원하도록 설계되었다. 한 코어의 출력은 인접한 다음 코어의 입력에 연결된다. SSN을 사용하는 칩에는 일반적으로 모든 코어를 통과하는 단일 SSN 데이터 경로(병렬 버스)가 있다. 평면도와 패드 위치에 따라 물리적 설계에서는 물리적으로 독립된 여러 개의 데이터 경로를 구현하는 것이 더 바람직할 수 있다. 또한 각 데이터 경로는 설정이 가능하며, IJTAG 네트워크의 SIB(Segment Insertion Bit)와 유사한 네트워크 세그먼트를 포함하거나 제외하도록 프로그래밍될 수 있는 먹스를 포함할 수 있다.
설계에서 SSN 구현
SSN을 활용하려면 표 1에 설명된 설계 방법을 따라야 한다. 예를 들어 IJTAG는 SSN 회로를 프로그래밍하는 데 사용되므로 IJTAG 인프라가 필요하다. 독립적 시프트 및 캡처를 활성화하려면 표준(Tessent 또는 타사) OCC가 필요하다. 이러한 요구사항과 권장 사항에 더 익숙해 질수록 SSN으로 전환하는 과정이 더 간단해진다.
-표1")
[표 1] SSN 준비 상태
실제 구현 전에 고려해야 할 두 가지 주요 사항이 있다. 첫째, 코어 레벨에서 압축(compression)은 독립된 해당 코어에 대해 최상의 결과(가장 작은 패턴 세트)를 제공하는 것에 맞춰 최적화되어야 한다. 칩 레벨 리소스나 계획된 SSN 버스 폭도 고려할 필요가 없다.
둘째, 칩 레벨에서는 사용 가능한 핀 수와 설계의 블록 다이어그램을 기준으로 SSN 버스를 계획해야 한다. SSN 데이터 경로는 설계의 물리적 영역을 고려하여 계획되어야 한다. 이 계획에서는 실제 연결 외에도 디버그 반환 경로에 필요한 먹스와 타이밍에 필요한 파이프라인을 계획한다. 어떤 영역을 병렬로 실행할 것인지 아니면 상대적 순서로 실행할 것인지는 계획할 필요가 없다.
실제 SSN 구현 플로우는 계층적 설계를 위한 Tessent Shell 플로우를 기반으로 하며, 그림 8에 나온 것처럼 메모리 BIST 등 다른 모든 Tessent DFT와 완벽하게 통합된다.
각 물리적 블록에 대해 상향식 DFT 삽입을 수행한 다음 상위 레벨에서 DFT 삽입을 수행한다. SSN은 EDT 압축 회로, OCC 및 이러한 블록 간의 연결과 함께 두 번째 DFT 삽입 단계 도중 설계에 삽입된다.
-8")
[그림 8] SSN 구현 플로우
DRC 및 전용 테스트벤치를 포함하는 포괄적인 SSN 검증 기능 세트를 전체 플로우에서 사용할 수 있으므로 잠재적 문제나 실수를 조기에 포착할 수 있다. SSN 삽입이 완료된 후, 합성 전에 ICLNetwork는 SSN 네트워크의 IJTAG 레지스터를 작성하고 읽을 수 있는지 확인하고, SSN 연속성 패턴은 SSN 네트워크를 확인한다. 플로우 후반부에 루프백 패턴은 스캔 패턴의 전체 시뮬레이션을 수행할 필요 없이 SSN 네트워크를 개별 코어까지 검증하는 데 도움이 된다.
고장 진단 플로우는 계층적 DFT 플로우와 사실상 동일하다. 테스터에서 캡처된 고장은 코어 레벨 고장에 리버스 매핑된다. 리버스 매핑 후에는 레이아웃 인식 진단이 제한 없이 수행된다.
업계 결과
Mentor와 Intel의 저자들이 2020 국제 테스트 컨퍼런스에서 발표한 ‘Streaming Scan Network(SSN): An Efficient Packetized Data Network for Testing of Complex SoCs’라는 연구에서 SSN은 기존의 핀 먹스 솔루션뿐만 아니라 다른 패킷 네트워크와도 비교되었다. 여기서 SSN은 테스트 데이터 볼륨을 각각 36%와 43% 줄이는 것으로 확인되었다. 테스트 사이클은 각각 16%, 43% 줄였다. SSN을 사용하면 다른 패킷 솔루션과 비교하여 설계 및 리타겟팅 플로우의 단계가 10배~20배 더 빠르다.
요약
이 문서에서 설명하는 SSN 기술은 복잡한 SoC에서 많은 스캔 자원 분배 문제를 해결한다. 칩 및 코어 레벨 DFT를 분리함으로써 칩 레벨 핀 수가 적은 경우에도 동시에 여러 개의 코어를 테스트할 수 있으며, 테스트 시간과 테스트 데이터 볼륨을 줄이기 위한 여러 가지 기능을 갖추고 있다.
거의 일정한 시간 안에 다수의 동일 코어 인스턴스를 테스트할 수 있고, 패턴 개수 및/또는 스캔 체인 길이가 일치하지 않는 코어가 있을 때 패딩을 최소화하고, 칩 전체에서 오가는 데이터를 빠르게 스트리밍할 수 있다.
설계 계획 및 구현을 단순화하고 특히 타일 기반 설계에 적합하다. SSN 구현 플로우는 계층적 설계를 위한 Tessent Shell 플로우를 기반으로 한다. SSN은 Tessent Test-Kompress™ 및 Tessent Diagnosis™에서 완벽하게 지원되며, Tessent MemoryBIST 및 Tessent LogicBIST 등 다른 모든 Tessent DFT 기술과 공존할 수 있다.






 |






 |
아날로그 설계를 위한 EDA 툴은 어떻게 진화하고 있는가?
조회수 821회 / Siemens EDA

전자제품 인터페이스의 설계 라이프사이클
조회수 598회 / David Wiens
전기 디자인 룰 체크(DRC)를 자동화하는 방법
조회수 1259회 /
 지멘스EDA 수석부사장.jpg)
2022년 시스템 및 설계 툴, 방법론의 시장 전망
조회수 1248회 / 지멘스
임계 영역을 이용한 자동차 IC의 테스트 품질 향상
조회수 1682회 / RON PRESS
SERDES 디자인을 위한 더 효율적인 솔루션이 있을까요?
조회수 1755회 / Neil Fernandes

지멘스 EDA 포럼 2021 열려, ‘Silicon to Systems’ 주제로 최신 설계 방...
조회수 1151회 / Joseph Sawicki
자동화된 EMC 분석을 PCB 레이아웃에 추가
조회수 1232회 / SIEMENS
DFT를 향한 성능 저하 없는 상향식 접근방식
조회수 2555회 / Geir Eide
PDF 다운로드
 |
회원 정보 수정
