2024 우수잡지


-MPLAB Software Updates-KR 466x58H.jpg)

CXL, CCIX 기반 PCIe 5와 SmartNIC은 어떻게 가속 솔루션을 혁신하고 있는가

글/스캇 슈바이처(Scott Schweitzer)
지난 30년 간 서버 기반 컴퓨팅은 많은 발전을 거듭해 왔다. 90년대에는 단일 소켓 독립형 서버에서 클러스터로의 전환이 이뤄졌고, 밀레니엄 시대에는 듀얼 소켓에 이어 멀티 코어 프로세서가 등장했다. 다시 10년이 지나면서 GPU는 그래픽을 넘어 크게 발전했으며, FPGA(Field Programmable Gate Array) 기반 가속기 카드의 출현도 확인할 수 있었다. 2020년에 이르러서는 DPU(Data Processing Unit)라고 하는 SmartNIC(네트워크 인터페이스 카드)이 주목을 받고 있다. SmartNIC은 거대한 FPGA와 멀티코어 ARM 클러스터에 기반하거나 심지어 이 둘을 조합하기도 한다. 이러한 진화는 솔루션 성능에 상당한 이득을 가져다준다. 주식 거래에서 유전자 염기서열 분석에 이르기까지 컴퓨팅은 보다 빨리 답을 제시해야 한다. 내부에서 도로의 역할은 PCIe(PCI Express)가 수행해 왔으며, 그 동안 상당한 변화를 겪기도 했지만, 대부분은 이를 기본적으로 사용하고 있다.
PCIe(Peripheral Component Interconnect Express)는 2003년에 처음 등장했으며, 네트워킹의 기본 인터커넥트 기능으로 기가비트 이더넷(GbE: Gigabit Ethernet)의 변화를 준비하는 시점에 도입되었다. 당시 미리넷(Myrinet)과 인피니밴드(Infiniband)와 같은 고성능 컴퓨팅(HPC: High Performance Computing) 네트워크는 각각 초당 2Gbps 및 8Gbps의 데이터 전송속도로 기가비트 이더넷을 넘어섰다. 얼마 후 성능이 뛰어난 10GbE NIC(Network Interface Card)이 등장했다. 이는 각 방향으로 약 1.25GB/s의 속도로 이동하기 때문에 8레인(x8) PCIe 버스는 시기적으로 적절하지 않았다. 그 당시에는 16레인(x16) 슬롯은 개념조차 없었으며, 서버 마더보드에 간혹 몇 개의 8레인 슬롯과 여러 개의 4레인 슬롯만 있었을 뿐이다. 비용을 절감하기 위해 일부 서버 공급업체들은 8레인 커넥터를 사용하기도 했지만, 우습게도 4레인만 연결할 수 있었다. 대부분의 설계자들은 PCIe 세대가 바뀔 때마다 속도가 두 배가 될 것으로 생각했다. 오늘날 4세대 PCIe 8레인 슬롯은 약 16GB/s에 적합하기 때문에 다음 세대는 약 32GB/sec 정도가 될 것이다. 또한 SmartNIC 또는 코프로세서 등의 가속기와 CPU 간의 효율적인 통신을 위해 개발된 두 가지의 새로운 프로토콜, CXL(Compute Express Link) 및 CCIX(Cache Coherent Interconnect for Accelerator)에 대한 희망도 제시되었다.
CXL에 대해 먼저 살펴보자. 이는 그림 1과 같이 CPU의 루트 컴플렉스가 가속기 카드와의 고대역폭 링크를 통해 캐시와 메인 시스템 메모리를 모두 공유할 수 있도록 잘 정의된 마스터-슬레이브 모델을 제공한다. 이를 통해 호스트 CPU는 가속기로 작업을 효율적으로 전달하고, 그 작업의 결과를 수신한다. 이러한 가속기 중 일부는 DRAM 또는 HBM(High-Bandwidth Memory) 등 상당한 규모의 고성능 로컬 메모리를 가지고 있다. CXL을 사용하면, 이러한 고성능 메모리를 호스트 CPU와 공유할 수 있기 때문에 공유 메모리의 데이터 세트 상에서 보다 쉽게 동작할 수 있다. 또한 아토믹 트랜잭션(Atomic Transaction)의 경우, CXL은 호스트 CPU와 가속기 카드 간의 캐시를 공유할 수 있다. CXL은 가속기와 호스트 통신을 개선하는데 기여하지만, PCIe 버스에서 가속기 간의 통신을 처리하지는 않는다.
-1")
[그림 1] CXL을 통해 연결되는 가속기의 개념 블록도(소스: ‘CXL(Compute Express Link) 사양, 2020년 7월’ 개정판 2.0, 버전 0.9, 31페이지)
2018년에 리눅스 커널은 마침내 PCIe P2P(Peer-to-Peer) 모드를 지원하는 코드를 출시했다. 이를 통해 PCIe 버스 상의 디바이스와 다른 디바이스 간의 데이터를 보다 쉽게 공유할 수 있게 되었다. 이 커널 업데이트 이전에도 P2P가 존재했지만, 두 피어 디바이스를 프로그램 방식으로 제어해야 하는 등 상당한 어려움이 뒤따랐다. 커널 변경으로 이제 가속기는 PCIe 버스 상의 PCIe/NVMe 메모리 또는 다른 가속기와 상대적으로 간단하게 통신이 가능하게 되었다. 하지만 솔루션이 더욱 복잡해짐에 따라 간단한 P2P로는 충분하지 않으며, 솔루션 성능이 제한될 수 있다. 오늘날에는 PCIe 버스와 직접 연결된 DIMM 소켓, NVMe 스토리지, 스마트 SSD(SmartSSD)에 상주하는 PMEM(Persistent Memory)을 비롯해 일부는 자체적으로 방대한 메모리를 가지고 있는 다양한 가속기 카드와 SmartNIC 또는 DPU 등이 존재한다. 이러한 디바이스들이 서로 통신을 수행하려면, 막대한 데이터 플로우로 인해 고가의 서버 프로세서에서 병목현상이 일어날 수 있다. 이러한 분야에 CCIX가 적용된다. 이는 PCIe 버스 상의 디바이스 간 P2P 관계를 설정하는 컨텍스트를 제공한다.
일부에서는 CCIX를 CXL과 경쟁하는 표준으로 간주하지만, 그렇지 않다. 버스 상에서 P2P를 연결하는 CCIX의 접근방식은 상당히 다르다(그림 2 참조). 또한 성능 특성이 각기 다른 여러 디바이스의 메모리를 함께 풀링하여 단일 NUMA(Non-Uniform Memory Access)로 매핑할 수 있다. 그런 다음 이 풀의 모든 디바이스가 전체 NUMA 메모리와 액세스할 수 있도록 가상 어드레스(Virtual Address) 공간을 설정한다. 이는 PCIe P2P의 단순한 메모리-메모리 방식이나 CXL을 이용한 마스터-슬레이브 모델을 훨씬 뛰어넘는다. NUMA는 1990년대 초반부터 개념적으로 존재했기 때문에 매우 잘 알려져 있다. 이를 기반으로 오늘날 대부분의 서버는 테라바이트(TB) 이상의 고가의 DRAM 메모리로 쉽게 확장할 수 있었다. 또한 SCM(Storage Class Memory)이라고도 하는 새로운 유형의 PMEM 메모리와 실제 메모리를 함께 매핑하여 대용량 메모리를 생성할 수 있는 드라이버도 제공된다. PCIe5와 CCIX를 사용하면, 시스템 설계자는 SmartSSD를 이용해 이 개념을 확장할 수도 있다.
-2")
[그림 2] 3개의 CCIX 구성 샘플(소스: ‘CCIXⓇ 소개 기술백서’ 5페이지)
컴퓨팅 스토리지로 알려진 SmartSSD는 컴퓨팅 디바이스(FPGA 가속기 등)를 SSD(Solid-State Drive) 내의 스토리지 컨트롤러와 나란히 배치하거나 컨트롤러 내부에 컴퓨팅 기능을 내장한 것이다. 이를 통해 SmartSSD의 컴퓨팅 디바이스는 드라이브에서 데이터가 나가고 들어올 때 데이터에 대한 작업을 수행할 수 있으며, 잠재적으로 데이터 액세스 및 저장 방식을 재정의할 수 있다. 초기에는 SmartSSD가 블록 디바이스로 보이기도 했지만, FPGA에 적절한 드라이버를 설치하면 바이트 주소지정이 가능한 스토리지로 만들 수 있다. 오늘날 SmartSSD는 수 테라바이트 용량으로 생산되고 있지만, 이러한 용량은 폭발적으로 증가할 것으로 보인다. 또한 SmartSSD는 NUMA를 통해서만 대용량 메모리 개념을 확장하는데 사용될 수 있기 때문에 호스트 CPU와 가속기 애플리케이션 모두 이 메모리를 사용하여 애플리케이션을 재작성하지 않고도 수많은 디바이스에서 수 테라바이트 메모리에 액세스할 수 있다. 또한 SmartSSD는 인라인(In-Line) 압축 및 암호화를 사용하여 더 나은 TCO 솔루션을 제공할 수 있다.
그렇다면 SmartNIC은 얼마나 이 아키텍처에 적합할까? SmartNIC은 PCIe 버스와 외부 네트워크 간의 연계 지점에 상주하는 특수한 형태의 가속기이다. SmartSSD는 컴퓨팅을 데이터에 근접하여 배치하는 반면, SmartNIC은 컴퓨팅을 네트워크에 근접하도록 배치하는 것이다. 이는 왜 중요할까? 간단히 말하면, 서버 애플리케이션은 네트워크 지연시간이나 정체, 패킷 손실, 프로토콜, 암호화, 오버레이 네트워크 또는 보안 정책에는 거의 관심이 없다. 이러한 문제를 해결하기 위해 지연시간을 개선하고, 정체를 줄이고, 패킷 손실을 복구할 수 있는 QUIC와 같은 짧은 지연시간을 제공하는 프로토콜이 개발되었다. 암호화와 전송 중인 데이터를 보호하기 위해 TLS가 만들어졌고, 이는 kTLS(Kernel TLS)로 확장되었다. 또한 가상 머신(Virtual Machine) 및 컨테이너 오케스트레이션(Container Orchestration)을 지원하기 위해 오버레이 네트워크가 개발되었다. 그 다음으로, 이를 정의하고 관리하는 OvS(Open vSwitch)와 같은 기술이 등장했으며, SmartNIC은 이 OvS를 오프로드한다. 마지막으로 정책을 통해 관리되는 보안이 있다. 이러한 정책은 캘리코(Calico) 및 타이게라(Tigera)와 같은 형태로 오케스트레이션 프레임워크에 반영될 것으로 예상된다. 또한 조만간 이러한 정책은 P4와 같은 프로그래밍 매치-액션(Match-Action) 프레임워크를 사용하는 SmartNIC으로 오프로드될 것이다. 이러한 모든 작업은 SmartNIC이라고 하는 특수 가속기로 오프로드 되어야 한다.
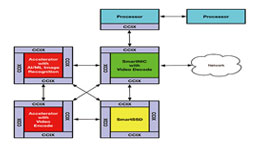
CCIX를 사용하면, 설계자는 여러 가속기가 단일 가상 어드레스 공간을 가진 하나의 거대한 메모리 공간인 SmartSSD 내부의 스토리지 및 실제 메모리와 직접 액세스할 수 있는 솔루션을 구현할 수 있다. 예를 들어, 그림 3과 같이 4개의 각기 다른 가속기를 사용하여 솔루션을 구성할 수 있다. SmartNIC은 비디오 디코더를 로드할 수 있어 카메라에서 비디오가 도착하면, 이를 비압축 프레임으로 다시 변환하여 NUMA 가상 어드레스 공간 내의 공유 프레임버퍼에 저장할 수 있다. 이러한 프레임을 사용할 수 있게 되면, AI(Artificial Intelligence) 이미지 인식 애플리케이션을 실행하는 두 번째 가속기가 이러한 프레임을 스캔하여 얼굴이나 번호판 등을 찾을 수 있다. 동시에 세 번째 가속기는 디스플레이 및 장기 저장을 위해 이러한 프레임을 트랜스코딩할 수 있다. 마지막으로 SmartSSD에서 실행되는 네 번째 애플리케이션은 AI 및 트랜스코딩 작업이 성공적으로 완료되면, 프레임버퍼에서 이러한 프레임을 제거한다. 여기에서 이러한 ‘스마트월드(SmartWorld)’ 애플리케이션을 구현하는 4개의 매우 특화된 가속기가 상호 협력하는 것을 알 수 있다.
-3")
[그림 3] CCIX 애플리케이션 사례(소스: 저자가 직접 구성한 수정된 CCIX 4c: 하이브리드 데이지 체인 모델)
업계는 무어의 법칙이 중단되면서 이를 상쇄시키기 위해 더 많은 코어를 추가하기 시작했다. 이로 인해 많은 수의 코어들이 사용되고 있지만, NIC이나 스토리지, 가속기와 같은 외부 디바이스와 CPU 간의 대역폭은 충분하지 않다. PCIe Gen5는 또 다른 도약이며, 이는 훨씬 큰 파이프를 통해 CPU에서 고성능 컴퓨팅을 수행할 수 있는 가능성을 열고 있다. 예를 들어, 일반적인 CPU 코어는 1Gbps 이상을 처리할 수 있지만, 듀얼 128 코어 CPU는 PCIe Gen4 x16으로는 충분하지 않다. 따라서 CXL과 CCIX가 제공하는 캐시 일관성을 이용하면, CPU 코어와 가속기 간의 긴밀한 상호작용을 필요로 하는 애플리케이션에 엄청난 이점을 제공할 수 있다. 데이터베이스, 보안, 멀티미디어와 같은 주요 애플리케이션 작업부하에서 이러한 이점을 활용하기 시작했다.
퍼즐의 마지막 조각은 오케스트레이션이다. 이는 쿠버네티스(Kubernetes)와 같은 프레임워크가 가속 하드웨어를 자동으로 검색 및 관리하고, 오케스트레이션 데이터베이스에서 온라인 및 사용 가능한 것을 표시할 수 있도록 해준다. 또한 이 하드웨어가 위에서 언급한 프로토콜 중 하나 이상을 지원하는지 알아야 한다. 새로운 솔루션 인스턴스에 대한 요청이 들어오고, 동적으로 스핀업되면서 이러한 첨단 프로토콜을 인식하고, 가속화하는 컨테이너 인스턴스가 이 하드웨어를 사용할 수 있다. 자일링스는 쿠버네티스와 함께 동작하고 풀에서 여러 FPGA 리소스를 관리하는 XRM(Xilinx Resource Manager)을 개발함으로써 전반적인 가속기 활용도를 향상시켰다. 이는 새로 배포된 애플리케이션 인스턴스가 인프라 내에서 가장 적절하고 성능이 뛰어난 리소스에서 실행되고, 정의된 보안 정책으로 유지되도록 자동으로 디스패치가 가능하다.
SmartNIC과 DPU는 PCIe 5와 CXL 또는 CCIX를 활용하여 복잡한 고성능 솔루션을 개발할 수 있는 충분한 상호연결 기능을 갖춘 가속기를 제공한다. 이러한 SmartNIC은 데이터센터나 여러 다양한 분야에서 다른 시스템과 컴퓨팅 집약적인 연결을 제공한다. 기본적으로 SmartNIC 리소스에서 실행되는 쿠버네티스 컨트롤러로 들어오는 명령을 컨테이너나 POD로 스핀업하는 미래를 상상해 볼 수도 있다. 이러한 새로운 작업부하를 위한 대규모 컴퓨팅은 서버의 호스트 CPU를 직접 사용하지 않고도, 해당 서버 내의 다른 위치에 있는 가속기 디바이스를 통해 수행이 가능할 수도 있다. 이 기능이 제대로 동작하려면, 캘리코와 타이게라를 능가하는 추가 보안 기능도 필요하다. 또한 여러 컴퓨팅 플랫폼에서 보안 영역이라고 하는 확장된 보안 컨텍스트를 위한 새로운 가속기 인식 보안 프레임워크도 필요하다. 이는 컨피덴셜 컴퓨팅(Confidential Computing)이 진입하고 있는 분야로, 단일 보안 영역 내에서 여러 컴퓨팅 플랫폼에 걸쳐 사용 중인 데이터를 보호할 수 있는 아키텍처와 API를 모두 제공해야 한다. 또한 국방부 건물 전체가 SCIF(Sensitive Compartmented Information Facility)가 되는 것처럼, 컴퓨터 내의 보안 영역은 여러 컴퓨팅 플랫폼에 걸쳐 확산되어야 한다. 앞으로 흥미로운 시대가 도래할 것이다.






 |






 |

알베오 U55C의 출시로 HPC 업계에 많은 가치 제공할 것
조회수 814회 / Nathan Chang

엣지 센서에서 CPU 가속기까지 ‘버설 AI 엣지 시리즈’
조회수 1020회 / Rehan Tahir

적응형 컴퓨팅, 포스트-무어의 법칙 시대에서 성장을 주도하다
조회수 1364회 / Victor Peng

데이터센터 혁신을 위한 장벽 없는 FPGA 솔루션
조회수 1005회 / Kartik Srinivasan 외 2인
자동차 시장의 혁신을 선도하는 자일링스의 DNA
조회수 741회 / Yousef Khalilollahi
CXL, CCIX 기반 PCIe 5와 SmartNIC은 어떻게 가속 솔루션을 혁신하고 있...
조회수 6822회 / Scott Schweitzer

대규모 5G 무선 구축을 위한 혁신적인 징크 RFSoC DFE
조회수 1499회 / Gilles Garcia
SmartNIC 아키텍처: 가속기로의 이행, 그리고 FPGA가 우위를 점하는 이유
조회수 4482회 / Scott Schweitzer

SmartNIC이 일반 NIC보다 뛰어난 이유는?
조회수 1874회 / Scott Schweitzer
PDF 다운로드
 |
회원 정보 수정