2024 우수잡지


-MPLAB Software Updates-KR 466x58H.jpg)







 |






 |
단일 IC로 구현한 포괄적 시스템 보호의 통합 솔루션
조회수 312회 / Anthony Huynh
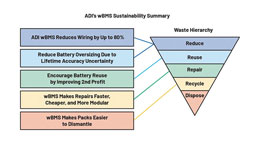
지속가능한 모빌리티를 가속화하는 진보한 전동화 기술
조회수 397회 / Patrick Morgan
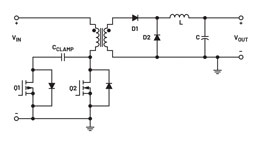
5G 및 차세대 통신 장비를 위한 향상된 -48VDC 전원 공급장치 설계
조회수 377회 / Hamed M. Sanogo

오픈소스 평가 플랫폼을 활용한 초음파 송신 서브시스템 프로토타이핑 방법
조회수 611회 / Sunshine Grace Cabatan 외 1인

밀리미터파 구현에 새로운 DPD 접근법이 필요한 이유와 가치 정량화 방법
조회수 833회 / Hossein Yektaii 외 2인
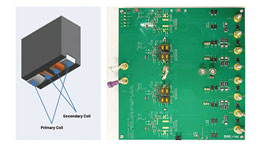
극히 빠른 동적 응답을 달성하는 유연한 TLVR 구조의 트랜스포머 기반 ...
조회수 729회 / Xingxuan Huang 외 2인

µModule 레귤레이터의 진화
조회수 608회 / Analog Devices

아나로그디바이스 양성환 전무 인터뷰, 고객의 성공에 기여하는 ADI 파...
조회수 925회 / Analog Devices
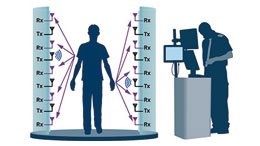
차세대 밀리미터파 스캐너를 가능케 하는 에지 프로세싱
조회수 805회 / Eamon Nash
PDF 다운로드
 |
회원 정보 수정
