2024 우수잡지


-MPLAB Software Updates-KR 466x58H.jpg)

임베디드 비전 애플리케이션의 머신 러닝

글/닉 니(Nick Ni), 아담 테일러(Adam Taylor), 자일링스
현재 임베디드 비전 분야에서 가장 뜨거운 주제 중 하나는 머신 러닝(Machine Learning)이다. 머신 러닝은 여러 업계의 주요 트랜드로 주목받고 있으며, 임베디드 비전(EV: Embedded Vision)뿐만 아니라 IIoT(Industry Internet of Things), 클라우드 컴퓨팅에서도 매우 중요한 역할을 하고 있다. 머신 러닝에 익숙하지 않은 사람들에게 이는 종종 신경망 생성 및 트레이닝으로 간주된다. 신경망이라는 용어는 매우 보편화되어 있지만, 일반적으로 구현되는 네트워크의 정확한 타입을 식별하는데 사용되는 상당히 많은 수의 서브 카테고리를 지정하는 별도의 이름들이 있다. 이러한 신경망은 각 뉴런이 입력을 받아 처리하고, 다른 뉴런과 통신하는 대뇌피질을 모델로 하고 있다. 따라서 신경망은 일반적으로 입력 레이어와 여러 숨겨진 내부 레이어, 그리고 출력 레이어로 구성된다.

가장 단순한 레벨의 뉴런은 입력을 받은 다음, 가중치를 적용하고, 가중된 입력의 합계를 기반으로 전달 함수를 수행한다. 이 결과는 숨겨진 레이어나 출력 레이어 내부의 다른 레이어로 전달된다. 사이클을 형성하지 않고 한 단계의 출력을 다른 단계에 전달하는 신경망을 FNN(Feed-forward Neural Networks)이라고 하며, Elman 네트워크처럼 피드백으로 사이클이 유도되는 신경망을 RNN(Recurrent Neural Networks)이라고 한다. 많은 머신 러닝 애플리케이션에서 매우 일반적으로 사용되는 용어 중 하나는 DNN(Deep Neural Networks)이다. 이는 보다 복잡한 머신 러닝 작업을 구현할 수 있는 여러 숨겨진 레이어를 가지고 있는 신경망이다. 신경망은 각 레이어 내에 사용되는 가중치와 바이어스를 결정하도록 트레이닝되어야 한다. 트레이닝하는 동안, 네트워크는 수많은 올바른 입력이나 잘못된 입력을 모두 가지고 있기 때문에 원하는 성능의 네트워크가 구현되도록 오류 함수가 적용된다. DNN 트레이닝은 요구되는 성능을 정확하게 트레이닝할 수 있도록 매우 많은 데이터 세트가 필요할 수 있다.
머신 러닝의 가장 중요한 용도 중 하나는 비전 지원 시스템에서 비전 가이드 자율 시스템으로 진화하고 있는 임베디드 비전 분야이다. 다른 간단한 머신 러닝 애플리케이션과 임베디드 비전 애플리케이션을 구분하는 것은 2차원 입력 포맷이다. 따라서 2차원 입력을 처리할 수 있는 CNN(Convolutional Neural Networks)이라고 불리는 네트워크 구조가 머신 러닝 구현에 사용된다. CNN은 최종 분류를 수행하기 위해 별도로 연결된 네트워크와 함께 여러 컨볼루션과 서브 샘플링 레이어를 포함하고 있는 FNN 유형에 해당한다. 또한 이러한 CNN의 복잡성으로 인해 딥 러닝(Deep Learning)으로 분류되기도 한다. 컨볼루션 레이어 내에서 입력 이미지는 여러 중첩된 작은 타일로 나눠진다. 이러한 컨볼루션의 결과는 최종적으로 완전히 연결된 네트워크(Fully Connected Network)에 적용되기 이전에, 추가 서브 샘플링 및 추가 단계를 거치기 전, 활성화 레이어를 사용하여 활성화 맵을 만드는데 사용된다. CNN 네트워크의 정확한 정의는 구현된 네트워크 아키텍처에 따라 다르지만, 일반적으로 다음 요소들을 포함하고 있다:
* 컨볼루션 - 이미지 내의 특징을 식별하는데 사용
* reLU(Rectified Linear Unit) - 컨볼루션 이후 활성화 맵을 생성하는데 사용되는 활성화 레이어
* 최대 풀링(Max Pooling) - 레이어 간의 서브 샘플링 수행
* 완전 연결 - 최종 분류 수행
이러한 각 요소들의 가중치는 트레이닝을 통해 결정되며, CNN의 장점 중 하나는 네트워크 트레이닝이 상대적으로 용이하다는 점이다. 가중치를 생성하는 트레이닝은 검출되기를 바라는 객체와 거짓 이미지에 대한 큰 이미지 세트를 필요로 한다. 이를 통해 CNN에 필요한 가중치를 만들 수 있다. 트레이닝 프로세스와 관련된 프로세싱 요건으로 인해 고성능 컴퓨팅을 제공하는 클라우드 기반 프로세서에서 실행되는 경우가 많다.
프레임워크
머신 러닝은 특히 네트워크와 아키텍처를 정의하고, 트레이닝 알고리즘을 생성하기 위해 매번 처음부터 시작해야 하는 복잡한 주제이다. 엔지니어들이 네트워크를 구현하고, 이 네트워크를 트레이닝하는 것을 돕기 위해 Caffe 및 Tensor Flow와 같은 여러 산업 표준 프레임워크들이 있다. Caffe 프레임워크는 머신 러닝 개발자들에게 Python 및 Matlab 바인딩을 비롯해 C++ 라이브러리 내의 사전 트레이닝된 가중치와 다양한 라이브러리 및 모델을 제공한다. 이 프레임워크는 사용자가 처음부터 시작할 필요없이 원하는 동작을 수행하기 위한 네트워크를 생성하고, 이를 트레이닝할 수 있도록 해준다. 재사용을 돕기 위해 Caffe 사용자는 원하는 경우 특정 작업을 위해 구현 및 업데이트할 수 있는 여러 네트워크 모델을 제공하는 model zoo를 통해 자신의 모델을 공유할 수 있다. 이러한 네트워크와 가중치는 prototxt 파일로 정의되며, 머신 러닝 환경에 구축되면, 이 파일은 추론 엔진을 정의하는데 사용된다...(중략)




™ 전원 솔루션.jpg)

 |






 |

알베오 U55C의 출시로 HPC 업계에 많은 가치 제공할 것
조회수 814회 / Nathan Chang

엣지 센서에서 CPU 가속기까지 ‘버설 AI 엣지 시리즈’
조회수 1020회 / Rehan Tahir

적응형 컴퓨팅, 포스트-무어의 법칙 시대에서 성장을 주도하다
조회수 1363회 / Victor Peng

데이터센터 혁신을 위한 장벽 없는 FPGA 솔루션
조회수 1005회 / Kartik Srinivasan 외 2인
자동차 시장의 혁신을 선도하는 자일링스의 DNA
조회수 741회 / Yousef Khalilollahi
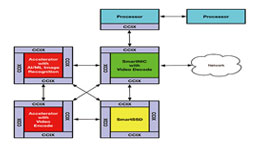
CXL, CCIX 기반 PCIe 5와 SmartNIC은 어떻게 가속 솔루션을 혁신하고 있...
조회수 6815회 / Scott Schweitzer

대규모 5G 무선 구축을 위한 혁신적인 징크 RFSoC DFE
조회수 1497회 / Gilles Garcia
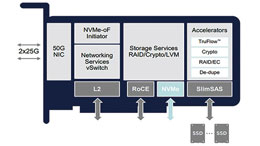
SmartNIC 아키텍처: 가속기로의 이행, 그리고 FPGA가 우위를 점하는 이유
조회수 4478회 / Scott Schweitzer

SmartNIC이 일반 NIC보다 뛰어난 이유는?
조회수 1871회 / Scott Schweitzer
PDF 다운로드
 |
회원 정보 수정